CARLA: Ein Hochschul-Archiv als vernetztes System
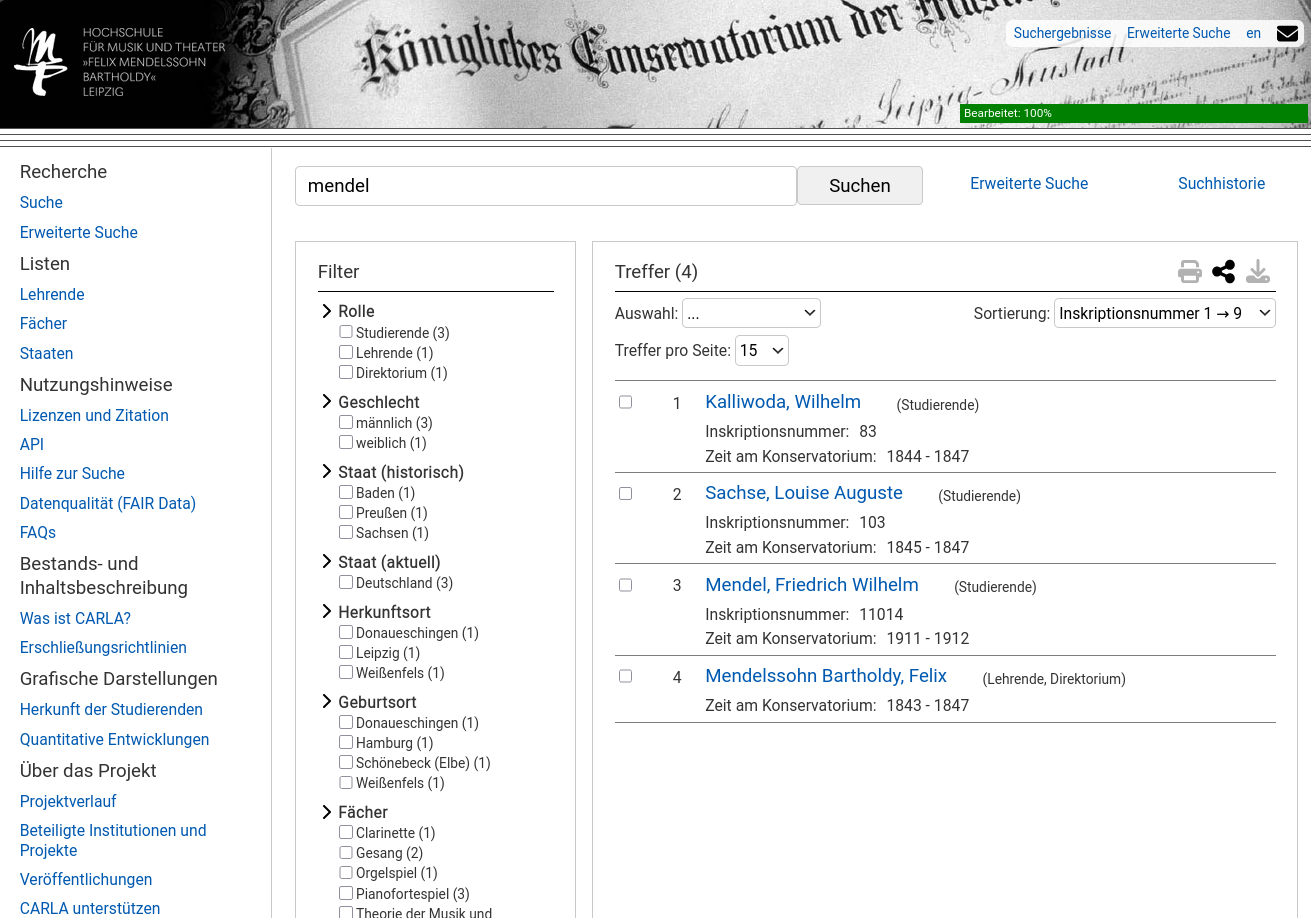
Stell dir vor, du hältst ein über hundert Jahre altes Matrikelbuch der Hochschule für Musik und Theater Leipzig in der Hand – handgeschrieben, vergilbt, voller Namen junger Menschen. Jeder Eintrag ist Kulturgeschichte. Und praktisch unauffindbar, solange er nur auf Papier existiert.
CARLA macht aus diesen Büchern eine durchsuchbare, vernetzte und weltweit zugängliche Forschungsdatenbank – von der Datenmodellierung bis zum laufenden Server.
Architektur: drei Schichten, klare Verantwortlichkeiten
CARLA ist bewusst als Drei-Schichten-System aufgebaut, jede Schicht mit einer Aufgabe und einem eigenen Repository:
- Vue/Vite Frontend -> Node/TypeScript API (tsoa) -> Tryton Domänenmodell (Python)
- Präsentation
- Vermittlung, typisiert
- Daten, Logik, Historie
Diese Trennung ist kein Selbstzweck: Sie hält das Domänenmodell frei von Transport-Belangen, macht die API unabhängig testbar und erlaubt es, das Frontend auszuliefern, ohne Backend-Internas preiszugeben.
Die Datenschicht: das eigentliche Herz
Der Kern ist ein Tryton-Modul mit einem umfangreichen relationalen Domänenmodell: hmt.person, hmt.document, hmt.inscription, hmt.directorium, hmt.staff, hmt.subject, hmt.course, hmt.geo_reference – verbunden über explizite Assoziationstabellen.
Vollständige Historisierung aller Änderungen auf den Kernmodellen.
Jede Änderung an einem Datensatz bleibt nachvollziehbar – für Quellenkritik und Provenienz im Archivkontext nicht verhandelbar.
Linked-Data-Anbindung auf Forschungsniveau:
- automatische Verknüpfung über die GND (Gemeinsame Normdatei)
- Verknüpfung zu Wikipedia
- Verweise auf Wikisource-Transkriptionen
- Anbindung RISM und Lobid
- Verknüpfung mit Digitalisaten auf sachsen.digital.
- Wikisource-Übersetzungen der Digitalisate
- GND-Wizard zum interaktiven Abgleich lokaler Datensätze gegen die Normdaten mit Dublettenerkennung
Die API-Schicht: typisiert und selbstdokumentierend
Die Vermittlungsschicht ist eine REST-API in Node.js / TypeScript auf Basis von tsoa.
Der Gewinn: Controller-Definitionen erzeugen automatisch OpenAPI-Spec und Express-Routen, Swagger-UI unter /api/docs ist immer synchron zum Code.
Die Präsentationsschicht: schnell, vernetzt, auffindbar
Das Frontend ist eine Vue 3 / Vite-Anwendung mit:
- Leaflet-Karte mit Marker-Clustering zur Herkunftsvisualisierung,
- Chart.js-Auswertungen zu Fächern, Zeiträumen und Geografie,
- vue-i18n für Mehrsprachigkeit,
- SSG/Prerendering und generierten Bot-Pages plus Sitemap für SEO – wichtig, damit historische Personen über Suchmaschinen auffindbar werden,
- Matomo (datenschutzkonformes Analytics) und Glitchtip fürs Error-Monitoring.
Staging und Production laufen als getrennte Podman-Pods: jeweils Nginx, PostgreSQL, Tryton, API (und Mailpit auf Staging). Gebaut wird das ganze als GitLab CI/CD mit branch-basiertem idempotenten Deployment.
Warum das den Unterschied macht
Dinge, die meine Arbeitsweise prägen:
- Architektur vor Feature-Akkumulation.
Saubere Schichten, explizite Verknüpfungsmodelle, Konfiguration über Environment – Entscheidungen, die in zwei Jahren noch tragen. - Die ganze Wertschöpfungskette in einer Hand. Datenmodell, API, Frontend, Containerisierung und CI/CD – ohne an jeder Schnittstelle die Verantwortung abzugeben.
- Echte Daten, echte Ansprüche.
Historisierung, Normdaten-Integration und Quellen-Verlinkung sind kein Beiwerk, sondern die fachliche Substanz.
CARLA verbindet ein Stück Leipziger Kulturgeschichte mit dem globalen Wissensnetz – als System, das nicht nur demonstriert, sondern produktiv läuft, gepflegt wird und Bestand hat.
https://carla.hmt-leipzig.de/