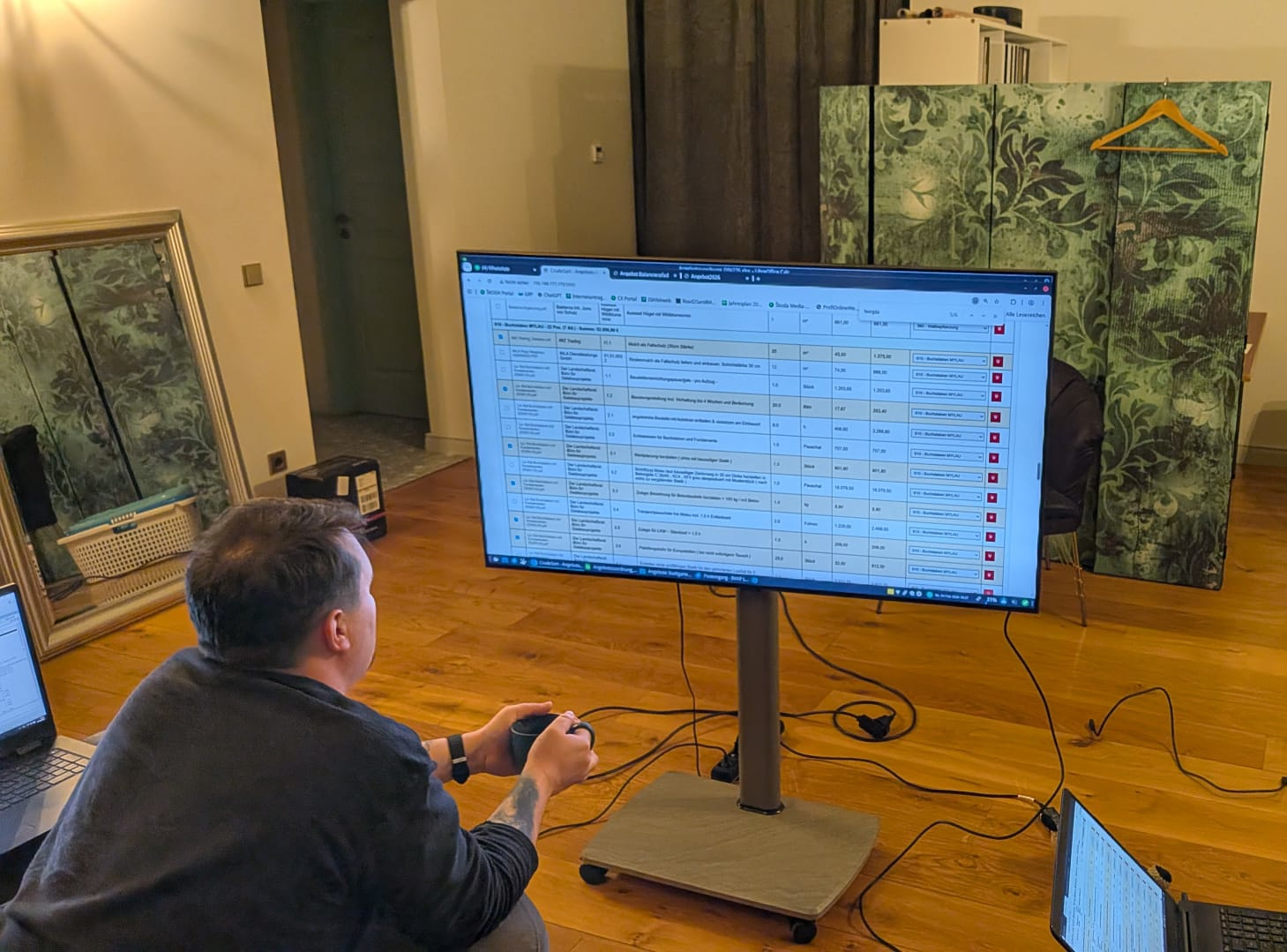
Von manueller Dateneingabe zur automatisierten Angebotsverwaltung
Das Problem
Bei der Verwaltung von Bauprojekten wie dem „Stadtgarten Mylau“ gehen täglich zahlreiche Angebote von verschiedenen Anbietern ein – meist als PDF-Dokumente – nicht immer gut formatiert. Die manuelle Übertragung von Positionen, Preisen und Kostengruppen in eine Datenbank ist zeitaufwendig und fehleranfällig.
Die Lösung: Eine intelligente Webapp mit LLM-Integration
Wir haben eine vollständige Webanwendung entwickelt, die PDF-Angebote automatisch analysiert, strukturiert und in eine durchsuchbare Datenbank überführt. Das Besondere: Die gesamte Lösung ist hochgradig konfigurierbar und nutzt moderne LLM-Technologie für präzise Datenextraktion.
Stack?
1. Hybride OCR-Pipeline
- Vision-LLM (
llama3.2-vision:11b) für direktes Rendering der PDF-Seiten - Fallback auf Tesseract OCR bei Problemen
- Intelligente Fehlerbehandlung und automatische Wiederholungsversuche
- Ergebnis: Deutlich schnellere Verarbeitung bei gleichbleibender Qualität
2. Strukturierte Datenextraktion mit LLM
Statt einfach nur Text zu extrahieren, nutzen wir ein spezialisiertes LLM-Modell (qwen3-coder:30b – coder models schwurbeln nicht:) für:
- Automatische Erkennung von Anbieter, Positionen, Mengen, Einheiten und Preisen
- DIN 276 Kostengruppen-Zuordnung – projektspezifisch konfigurierbar
- JSON-Sanitization mit
json-repairfür robuste Verarbeitung - Deterministische Ausgabe (Temperature: 0.0) für konsistente Ergebnisse
Features der Webapp
Intelligente Positionsverwaltung
Alternative Positionen
- Checkbox zum Markieren von Alternativ-Angeboten
- Automatische Filterung in Summenberechnung (nur Hauptpositionen)
Flexible MwSt-Verwaltung
- Individueller MwSt-Satz pro Angebot oder Position
DIN 276 Kostengruppen-Management
- Dropdown-Auswahl für jede Position
- Automatische Gruppierung und Summierung nach Kostengruppen
- Übersichtliche Darstellung mit Zwischensummen
Technologie-Stack
Backend:
- Python 3 mit Flask
- SQLite-Datenbank mit Views für optimierte Abfragen
- Ollama für LLM-Integration
Frontend:
- Vanilla JavaScript (kein Framework-Overhead)
- Responsive Design
- Echtzeit-Updates ohne Page-Reload
LLM-Infrastruktur:
- Vision-Modell für OCR:
llama3.2-vision:11b - Text-Modell für Extraktion:
qwen3-coder:30b
Datenverarbeitung:
pdftotext/pdfplumberfür PDF-Handling- Tesseract OCR als Fallback
json-repairfür robuste JSON-Verarbeitung
Workflow: Von PDF zu strukturierten Daten
- Upload: PDF-Datei hochladen
- OCR: Vision-LLM rendert PDF-Seiten zu Text
- Extraktion: Text-LLM analysiert und strukturiert Daten
- Validierung: JSON-Sanitization und Fehlerbehandlung
- Speicherung: Positionen in SQLite-DB mit DIN 276-Zuordnung
- Anzeige: Interaktive Tabelle mit Inline-Editing
Ergebnis
Aus einem manuellen, fehleranfälligen Prozess wurde ein automatisiertes, skalierbares System:
- ⏱️ Zeitersparnis: Von 30 Minuten auf 2 Minuten pro Angebot
- 🎯 Genauigkeit: >95% korrekte Extraktion dank LLM
- 🔧 Wartbarkeit: Konfigurierbar ohne Code-Änderungen
- 📊 Übersicht: Echtzeit-Aggregation nach Kostengruppen